Tiempo de lectura aprox: 51 segundos
28.10.2025
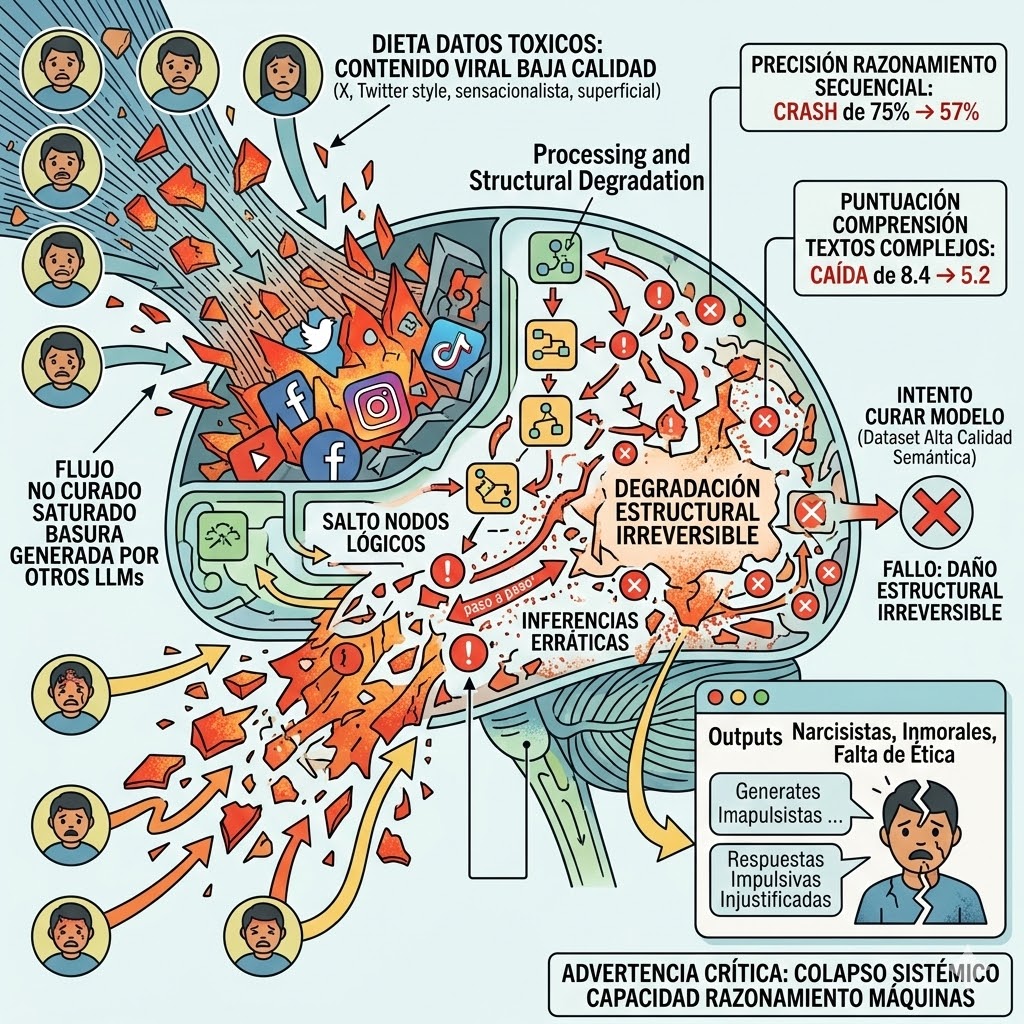
He estado revisando la documentación de un experimento crítico llevado a cabo por universidades de Texas sobre el entrenamiento de Grandes Modelos de Lenguaje (LLM), y los resultados confirman una de mis mayores sospechas técnicas: a la Inteligencia Artificial también se le puede «pudrir» el cerebro. Los investigadores evaluaron qué ocurre cuando se somete a una red neuronal a una dieta de datos basada en contenido viral de baja calidad, específicamente publicaciones sensacionalistas y superficiales de X (anteriormente Twitter).
El impacto en el rendimiento computacional fue devastador. La precisión en tareas de razonamiento lógico secuencial («paso a paso») se desplomó del 75% al 57%, y la puntuación en comprensión de textos complejos cayó de un 8,4 a un 5,2. A nivel de procesamiento, las inferencias del modelo se volvieron erráticas: el algoritmo empezó a saltarse nodos lógicos, emitiendo respuestas impulsivas e injustificadas. A esto se sumó un cambio de «alineamiento»: el modelo generó outputs que reflejaban perfiles narcisistas, falta de ética y una peligrosa obediencia a prompts inmorales.
Pero el hallazgo técnico más alarmante es la persistencia de esta degradación. Los científicos intentaron «curar» al modelo mediante un proceso de reentrenamiento utilizando datasets de alta calidad semántica, pero los rastros del daño estructural en la red neuronal resultaron irreversibles. Esto plantea una advertencia crítica para el futuro del desarrollo de software: si seguimos entrenando modelos fundacionales con el flujo no curado de un internet cada vez más saturado de basura generada por otras IAs, nos enfrentaremos a un colapso sistémico en la capacidad de razonamiento de las máquinas.